
Este proyecto combina mi background en salud con técnicas de ciencia de datos para resolver una necesidad real en consulta: ¿Podríamos predecir el riesgo de lesión de un paciente antes de que ocurra?
Engloba análisis clínico, decisión de qué métricas usar, exploración visual para entender patrones y el desarrollo de un modelo de machine learning (Random Forest).
Objetivo del proyecto: Diseñar un modelo de clasificación que, con al menos un 73% de precisión, detecte el riesgo de lesión de rodilla utilizando variables biomecánicas reales.
Tecnologías y herramientas
- Python, Pandas, Scikit-learn
- GridSearchCV, Random Forest, validación cruzada
- Visualización con Matplotlib y Seaborn
- Documentación en Jupyter Notebooks
El origen de una necesidad real
Durante ocho años trabajé como podóloga en mi propia clínica. Cada día, evaluaba pacientes con diferentes perfiles biomecánicos, algunos con lesiones recurrentes, otros en riesgo potencial. La pregunta siempre era la misma: ¿podríamos anticiparnos a la lesión antes de que ocurra? Los profesionales de la salud dependemos de nuestra experiencia y ojo clínico, pero ¿y si pudiéramos respaldar esas intuiciones con datos objetivos y modelos predictivos?
Esta inquietud latente encontró su oportunidad cuando el equipo de investigación de la Universidad San Jorge de Zaragoza me proporcionó acceso a un dataset confidencial con información biomecánica de casi 900 pacientes. Era el momento de convertir años de observación clínica en un sistema predictivo basado en evidencia.
Del caos de datos clínicos al orden analítico
El primer desafío fue enfrentarme a la realidad de los datos sanitarios: heterogéneos, incompletos y complejos. Cualquiera que haya trabajado con información clínica sabe que cada profesional registra de forma diferente, cada prueba tiene sus particularidades y los datos faltantes son la norma, no la excepción.
Durante dos meses intensivos, transformé ese caos inicial en información estructurada. La limpieza de datos fue quirúrgica: eliminé columnas con más del 75% de valores nulos, calculé variables derivadas como el IMC, y tomé decisiones críticas sobre qué conservar y qué descartar. Cada decisión requería equilibrar el rigor estadístico con el conocimiento clínico: algunos outliers que matemáticamente parecían errores, eran casos reales pero extremos que un profesional reconocería inmediatamente.
La evolución hacia un modelo específico
Inicialmente, desarrollé un sistema integral para predecir lesiones musculoesqueléticas generales, desplegado en Google Cloud Platform con Flask. Era ambicioso y funcional, pero el análisis de los datos reveló algo importante: las lesiones de rodilla dominaban el dataset. Fue entonces cuando tomé la decisión estratégica de especializar el modelo.
Esta segunda fase se centró exclusivamente en la rodilla, no por capricho, sino por pragmatismo basado en datos. Si queríamos un modelo realmente útil para la práctica clínica, debíamos enfocarnos donde teníamos más información y donde el impacto sería mayor.
El proceso de selección del modelo perfecto
Evalué múltiples algoritmos de clasificación: Bagging Classifier, Decision Tree, Gradient Boosting, Voting Classifier... pero el Random Forest destacó por su equilibrio entre interpretabilidad y rendimiento. En el contexto clínico, no solo importa la precisión; necesitamos entender por qué el modelo toma sus decisiones.
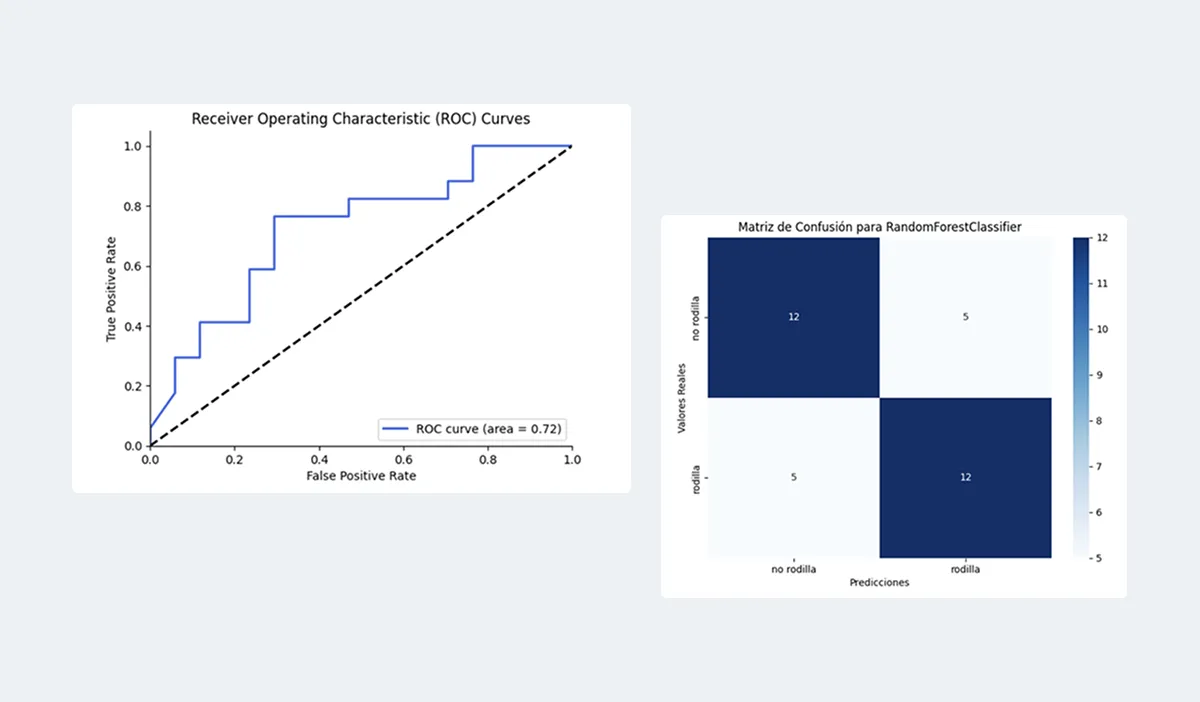
La optimización fue meticulosa. Utilicé GridSearchCV con validación cruzada de 10 folds, ajustando hiperparámetros hasta encontrar la combinación óptima. El modelo final alcanzó un 73.5% de precisión en test y, más importante aún, un 76% de recall para lesiones de rodilla. En medicina, detectar correctamente los casos positivos es crucial: es preferible una falsa alarma que pasar por alto un riesgo real.
Descubrimientos que desafían las intuiciones
El análisis reveló patrones fascinantes que a veces contradecían las expectativas clínicas tradicionales. El Ground Shock mostró una correlación significativa con el riesgo de lesión, mientras que variables demográficas como peso y altura, tradicionalmente consideradas importantes, tuvieron menos relevancia de la esperada.
Estos hallazgos no solo validan el enfoque data-driven, sino que abren nuevas líneas de investigación. ¿Estamos prestando atención a los parámetros correctos en la evaluación clínica? ¿Qué otros patrones ocultos esperan ser descubiertos?
El desafío del desbalanceo y las decisiones difíciles
El mayor reto técnico fue el desbalanceo de clases. En datos médicos reales, afortunadamente, los casos sanos suelen superar a los patológicos. Exploré técnicas avanzadas como SMOTE y PCA, pero finalmente opté por una solución más elegante: centrarme en la calidad de las features y aprovechar mi conocimiento del dominio clínico.
La segmentación inicial por zonas específicas del miembro inferior no funcionó como esperaba. Esta “falla” fue una lección valiosa: a veces, la solución no está en complicar el modelo, sino en comprender mejor el problema y ajustar el enfoque.
Reconocimiento científico y visión de futuro
El proyecto fue presentado en el 11º Congreso Conjunto de la AEA y SEROD en Barcelona, validando su relevancia en la comunidad científica. Ver cómo la inteligencia artificial puede transformar el análisis biomecánico y potencialmente prevenir lesiones es profundamente motivador.
Actualmente, el sistema está en fase de mejora. La aplicación web se encuentra pausada mientras trabajamos en aumentar la muestra y balancear las clases. El objetivo no es solo mejorar las métricas, sino crear una herramienta que realmente marque la diferencia en la práctica clínica diaria.
Reflexión personal: donde la tecnología encuentra su propósito
Este proyecto representa la convergencia perfecta entre mi experiencia clínica y mis habilidades técnicas. Cada línea de código está respaldada por años de observación directa de pacientes, cada decisión de modelado considera la realidad práctica de una consulta.
La tecnología tiene sentido cuando resuelve problemas reales. Este clasificador no es solo un ejercicio académico; es una herramienta con el potencial de ayudar a profesionales de la salud a tomar decisiones más informadas y, en última instancia, mejorar la calidad de vida de los pacientes.