La necesidad de respuestas inmediatas
Al gestionar la web de un importante distribuidor de productos promocionales, nuestro equipo se enfrentaba a un desafío constante: su catálogo de casi 5.000 productos dependía íntegramente de la API de un proveedor externo, Makito. La sincronización de datos había sido implementada por un tercero, convirtiendo el proceso en una caja negra para nosotros.
Esta falta de visibilidad creaba un cuello de botella operativo. Cuando el cliente preguntaba ¿las categorías son consistentes? ¿el stock mostrado es correcto? ¿las técnicas de marcaje están unificadas?, nuestras respuestas eran lentas y reactivas. Necesitábamos una forma rápida de auditar y entender los datos que alimentaban su plataforma.
Investigación y arquitectura de la solución
Mi primera acción fue mapear completamente la API de Makito. Usando Postman, realicé pruebas exhaustivas de autenticación y exploré cada endpoint disponible. Este proceso inicial fue crucial para entender la estructura de datos y planificar la arquitectura del sistema.
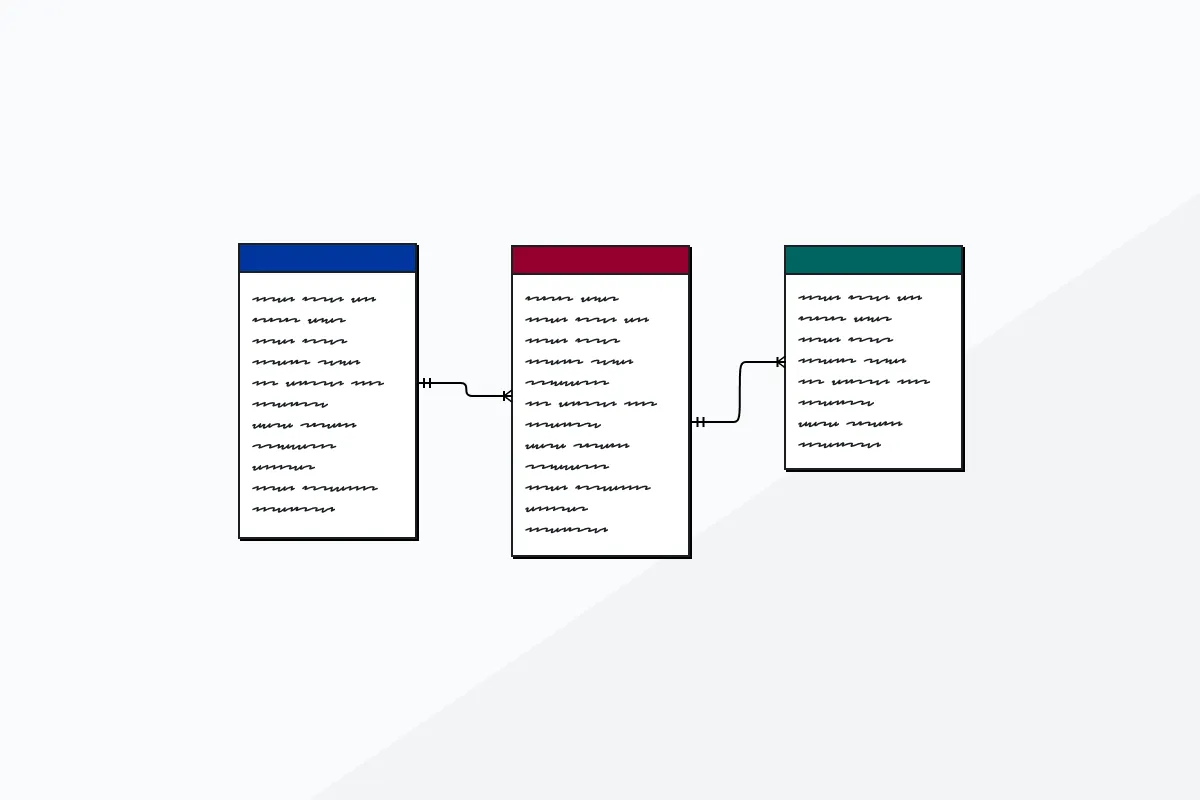
Con la información obtenida, creé un diagrama detallado en Miro que mapeaba las relaciones entre los diferentes endpoints de la API: productos, categorías, colores, técnicas de marcaje, stock, precios… Esta visualización se convirtió en la hoja de ruta para el desarrollo.

Construcción del pipeline
Con una comprensión clara de la API, desarrollé en solo una semana un conjunto de scripts en Python que nos dieron la visibilidad que necesitábamos:
- Autenticación segura: Un script dedicado a obtener y gestionar el token de autenticación de la API, manejando las credenciales de forma segura.
- Extracción automatizada: Un script principal que consultaba sistemáticamente todos los endpoints clave, descargando la información completa en formato JSON.
- Procesamiento inteligente: Funciones específicas para limpiar, aplanar y estructurar los datos, convirtiéndolos en archivos CSV y JSON listos para el análisis.
- Análisis exploratorio: Con Jupyter Notebooks y Pandas, pude explorar el catálogo, identificar valores únicos y generar resúmenes estadísticos al instante.
La elección de Python fue estratégica por su su potente ecosistema para el análisis de datos. Diseñé el sistema de forma modular, permitiendo al equipo ejecutar análisis específicos según la necesidad del momento.
fetch_token.py # Autenticación segura y gestión de tokens
fetch_products.py # Extracción sistemática de todos los endpoints
process_json.py # Limpieza y estructuración de datos
analyze_data.py # Análisis y generación de reportes
extract_keywords_csv.py # Exportación de datos específicosEsta modularidad permitía al equipo verificar categorías un día, auditar stock al siguiente o analizar técnicas de marcaje cuando surgían dudas, haciendo que la herramienta fuera flexible y extremadamente útil en el día a día.
Mapeo de endpoints
El primer paso fue crear un diccionario exhaustivo de todos los endpoints disponibles en la API. La parametrización con variables como el idioma (español = 1) y los incrementos de precio garantizaba que obtuviéramos exactamente la información que el cliente necesitaba para el mercado español.
ENDPOINTS = {
"products": "/products",
"categories": "/categories/1", # 1 = Español
"colors": "/colors/1", # 1 = Español
"descriptions": "/descriptions",
"descriptionslang": "/descriptionslang/1", # 1 = Español
"descriptionextlang": "/descriptionextlang/1", # 1 = Español
"images": "/images",
"stock": "/stock",
"stockVariants": "/stockVariants",
"prices": "/prices",
"prices": "/prices/10", # Ejemplo con incremento de 10%
"variants": "/variants",
"markingTechniques": "/markingTechniques/1", # 1 = Español
"markingTechniquesTypes": "/markingTechniquesTypes",
"markingTechniquesPrices": "/markingTechniquesPrices",
"markings": "/markings",
"markingsTranslations": "/markingsTranslations/1", # 1 = Español
"keywords": "/keywords",
"observations": f"/observations/{REF_PRODUCT_EXAMPLE}/1", # 1 = Español
}Extracción de datos en formato JSON
El corazón del proceso de extracción era un script que, utilizando la librería requests de Python, realizaba una solicitud GET a cada endpoint, pasando el Bearer token en las cabeceras para la autenticación. La respuesta de cada endpoint, un archivo JSON, era capturada y guardada localmente.
def fetch_data(token, endpoint, output_dir):
"""
Realiza una solicitud GET a un endpoint y exporta los datos obtenidos en formato JSON.
Args:
token (str): Token de autenticación.
endpoint (str): URL del endpoint.
output_dir (str): Directorio donde se guardará el archivo exportado.
Returns:
None
"""
url = f"{BASE_URL}{endpoint}"
headers = {"Authorization": f"Bearer {token}"}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
# Exportar los datos a un archivo JSON
filename = endpoint.strip("/").replace("/", "_") + ".json"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)
print(f"Datos exportados correctamente: {filepath}")
except requests.exceptions.RequestException as e:
print(f"Error al obtener datos del endpoint {endpoint}: {e}")Impacto en el negocio
Este pipeline interno se convirtió en una herramienta estratégica que generó un impacto directo y medible en el negocio de nuestro cliente. Transformamos la incertidumbre en control, permitiéndonos pasar de ser reactivos a proactivos.
El análisis de los datos reveló inconsistencias clave, como categorías duplicadas con nombres ligeramente diferentes que fragmentaban el catálogo y confundían a los usuarios. Mis reportes permitieron al cliente tomar decisiones informadas para:
- Unificar y simplificar categorías, reduciendo redundancias y mejorando la navegabilidad del catálogo
- Estandarizar nomenclaturas en técnicas de marcaje y zonas de impresión, creando consistencia en toda la plataforma
- Verificar la integridad del stock, detectando discrepancias entre la API y lo mostrado en web
- Optimizar para SEO, consolidando la estructura de productos para mejorar el posicionamiento en buscadores.
El valor de la agilidad analítica
Este proyecto demuestra que no todos los análisis de datos necesitan meses de desarrollo o infraestructuras complejas. A veces, el mayor valor está en proporcionar respuestas rápidas y precisas que permitan tomar decisiones inmediatas.
En una semana, transformé una API opaca en una fuente transparente de insights. Los scripts que desarrollé siguen siendo utilizados por el equipo cuando necesitan verificar información o analizar nuevos aspectos del catálogo. Es un recordatorio de que las mejores soluciones técnicas son las que resuelven problemas reales de negocio.
Este proyecto demuestra la importancia de entender y controlar el ciclo de vida completo de los datos, incluso cuando provienen de fuentes externas.